June 29, 2026 · AI Strategy
The most interesting AI stories today are not about a model writing faster, coding faster, or summarizing faster.
They are about AI entering places where a wrong answer has consequences.
A person asks Claude for a second opinion on an MRI. A university professor finds a large AI cheating case. European lawmakers debate scanning private messages. A new multimodal guardrail benchmark treats safety policy as something that changes at runtime. GLM 5.2 beats Claude Code in one security benchmark while a purpose-built security pipeline still performs better.
At first, these look like separate stories.
They are not.
They all point to the same product shift:
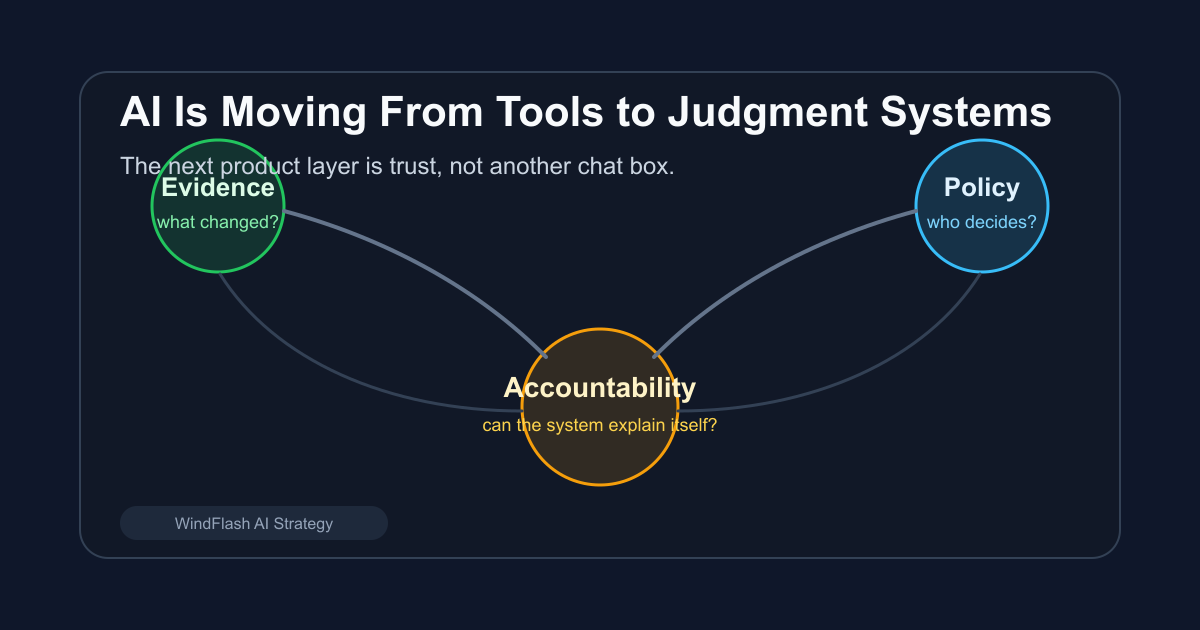
AI is moving from tools that help us produce output to systems that participate in judgment.
That changes the product problem completely.
The old AI product question was: can it do the task?

The first consumer AI wave was judged by visible output.
Could it write a memo? Could it summarize a PDF? Could it generate code? Could it create an image? Could it answer a customer support question?
That was a natural starting point. Output is easy to evaluate. A user can see whether the draft is useful, whether the image looks good, whether the code compiles, whether the summary captures the main idea.
But the next wave is different.
The question is no longer only:
Can the model produce something?
The question is:
Should this system be trusted inside a decision?
That is a much harder product standard.
When an AI model helps with a medical second opinion, the issue is not just whether the output is fluent. The issue is whether the system can show evidence, uncertainty, limits, and escalation paths. When AI is used in education, the issue is not just whether students can generate better answers. The issue is whether the institution can still define authorship, assessment, and fairness. When AI is used in cybersecurity, the issue is not just whether a model finds vulnerabilities. The issue is whether the workflow can separate model capability from verification scaffolding.
This is why “better model” is not a complete product strategy anymore.
The Claude MRI story is really about evidence
The MRI story is powerful because it is so concrete.
In the source article, the author used Claude Opus 4.8 to review shoulder MRI files and found that the model’s interpretation conflicted with the human medical report. The article says the human doctor saw a Grade III partial-thickness tear, while Opus reported an intact tendon.
That does not mean the AI was right.
It also does not mean the doctor was wrong.
The real point is that a normal person can now run a serious-looking second analysis on complex medical data. That creates a new layer in the healthcare experience: the patient arrives with generated evidence, generated questions, and generated doubt.
For product builders, the lesson is simple:
If your AI product enters a high-trust workflow, the output cannot stand alone.
It needs to answer:
- What evidence did it use?
- What did it ignore?
- How confident is it?
- What would change its conclusion?
- When should a human expert take over?
An AI medical assistant that only produces a confident paragraph is dangerous. An AI medical assistant that shows the relevant frames, explains uncertainty, and recommends professional review is a very different product.
The difference is not model quality alone.
The difference is accountability design.
SingGuard shows where safety products are going
Static moderation is too brittle for the next phase of AI.
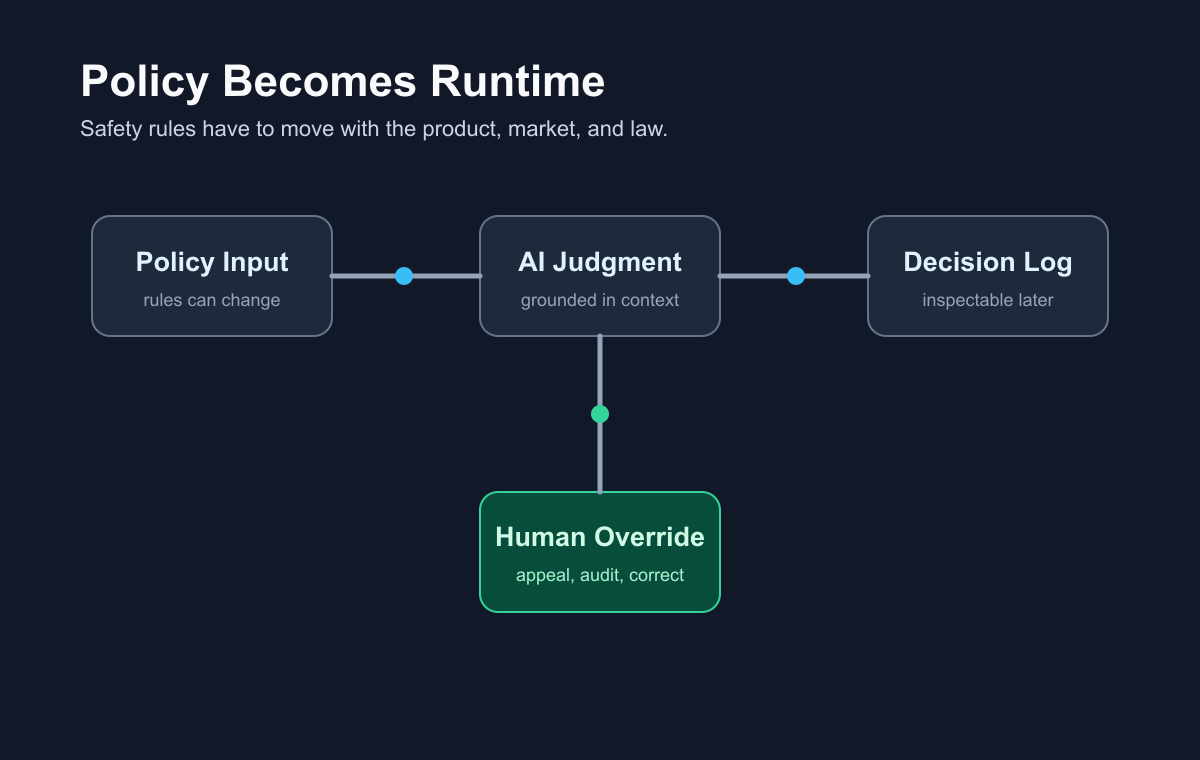
That is why SingGuard is interesting. It treats the active safety policy as a runtime input and performs rule-by-rule, policy-grounded judgment. Its benchmark covers 56,340 examples across more than 80 fine-grained risk types.
This matters because real policy changes.
Company rules change. Local law changes. Platform norms change. A healthcare use case does not need the same policy boundary as a game chat, an education tool, a security assistant, or a customer support workflow.
The old product model was:
Build a filter, ship it, tune it occasionally.
The new product model is:
Treat policy as part of the runtime system.
That means the best AI safety tools will look less like a single classifier and more like an operating layer:
- policy input
- evidence extraction
- rule-by-rule reasoning
- decision logs
- appeals and overrides
- evaluation against changing benchmarks
This is also why safety will become a product surface, not just an internal feature.
Users will want to know not only what the model answered, but which rule shaped the answer.
The EU Chat Control fight is the policy mirror image
The EU Chat Control debate shows what happens when institutions respond to technical risk with surveillance.
In Patrick Breyer’s report, the concern is that private communications could be subjected to scanning mandates through political negotiation rather than transparent public debate.
Whether one agrees with every claim or not, the product lesson is clear: once a technology makes new forms of detection possible, institutions will be tempted to mandate those capabilities.
That puts product builders in a difficult position.
The same AI techniques that can detect abuse can also normalize mass scanning. The same safety infrastructure that can reduce harm can also become a control layer. The same audit trail that can create accountability can become a surveillance record.
So the question cannot be “can we detect it?”
The better question is:
What power does this detection system create, and who can use it?
This is where privacy-preserving design, minimization, local processing, narrow warrants, and transparent governance stop being policy buzzwords. They become product architecture.
Education is the warning sign
The Brown University cheating story is not just about students using AI badly.
It is about institutions losing the assumptions that made their evaluation systems work.
Traditional exams assume limited access, individual effort, and reasonably observable authorship. AI breaks all three. If a student can produce polished reasoning at any moment, the institution has to decide whether to ban, detect, redesign, or integrate.
Most institutions will try all four.
But the deeper lesson applies beyond education.
Any workflow built on scarcity of expertise is going to be stressed by AI abundance:
- legal drafting
- medical triage
- software review
- financial analysis
- academic writing
- compliance work
The old gatekeeping mechanisms will not disappear overnight. But they will have to explain themselves.
That creates an opportunity for products that help institutions redesign evaluation rather than simply police usage.
GLM 5.2 shows why raw capability is not enough
The Semgrep benchmark is a useful reminder that model comparisons are tricky.
In Semgrep’s security benchmark post, GLM 5.2 scored higher than Claude Code on IDOR detection in a prompt-only setup, at a much lower cost per vulnerability found. But Semgrep’s own specialized pipeline still performed better than either raw model setup.
That is the pattern to watch.
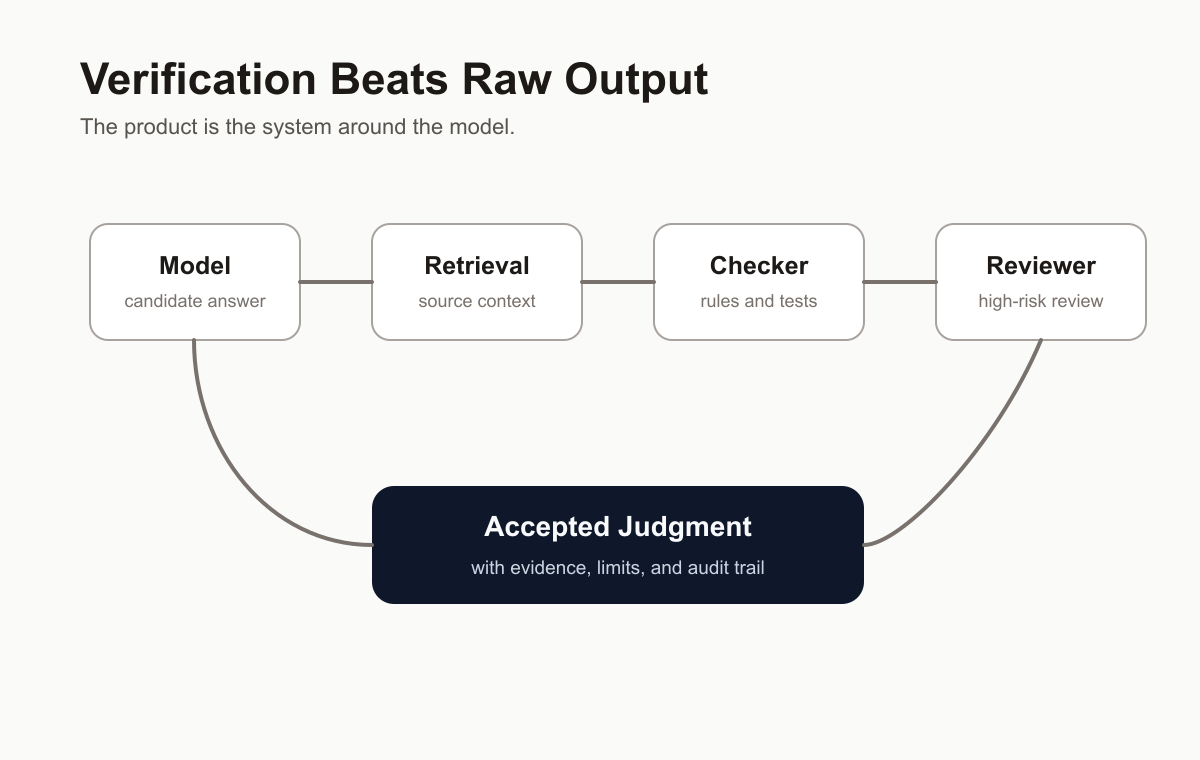
In real products, the winning system is rarely “the best model by itself.”
It is the model plus:
- retrieval
- task framing
- structured output
- validation
- domain-specific heuristics
- human review
- cost controls
This is especially true in judgment-heavy work. A cheaper open-weight model may be good enough for one layer. A stronger model may be needed for escalation. A deterministic checker may matter more than either. A human may be required at the final step.
The product is the system, not the model.
The next AI product layer is trust
For founders and developers, the practical takeaway is not “add governance.”
That phrase is too vague.
The real takeaway is to design trust as a first-class product layer.
A serious AI judgment product should show five things:
1. Evidence
What source, file, image, log, or quote led to the answer?
2. Boundaries
What is the system allowed to decide, and what must be escalated?
3. Uncertainty
What would make the system less confident?
4. Policy
Which rule, standard, or workflow shaped the decision?
5. Accountability
Who can inspect, override, appeal, or audit the result?
This does not make the product slower. Done well, it makes the product usable in more serious environments.
The future of AI products is not just better answers.
It is better answers that can survive contact with responsibility.
Sources
- Using Claude to get a second opinion on my MRI
- SingGuard: A Policy-Adaptive Multimodal LLM Guardrail with Dynamic Reasoning
- Double threat to private communications: Chat Control backroom deals
- AI fraud at Brown University: academic integrity is at risk
- GLM 5.2 beats Claude in Semgrep cybersecurity benchmarks
- WindFlash AI Daily Report: June 29, 2026