
面向开发者/产品/研究同学的长文评测:本文只关注最近一个月(2026-01-15~2026-02-15)中国团队发布的开源/开放权重新模型与重要新分支,尝试回答一个更工程的问题:
当我们要做编程 Agent(OpenClaw / SWE-Agent / Claude Code 类)时,哪些新模型是真正“可用”的?它们分别解决了什么?代价是什么?
说明:文中所有关键数字(如 SWE-bench Verified、BrowseComp 等)均来自对应团队的官方博客、技术报告、GitHub README 或 HuggingFace 模型卡。
0. 这一个月发生了什么?一句话总结
如果把 2024~2025 的主线概括为“开源模型追上可用性”,那么 2026 年开年这一个月最明显的变化是:
- 模型不再只谈能力,而是直接谈“Agent落地方式”:上下文管理(context management)、工具调用(tool use)、并行多代理(swarm)、真实环境 RL(environment RL)、以及与现成编码 Agent 的兼容。
- 评测口径更贴近真实任务:SWE-bench Verified(修 bug)、BrowseComp(带浏览器检索/阅读)、HLE-with-tools(带工具的复杂考试)、以及“耗时/成本/调用次数”这类“能否上线”的指标。
你会看到不少发布材料甚至不再把“模型参数”放第一位,而是强调:
- “给我一个 repo,我能改对代码并通过测试(SWE Verified)”
- “给我一个问题,我能自己上网查、读、总结(BrowseComp + context management)”
- “给我一个复杂任务,我能拆成 100 个子 agent 并行做(Agent Swarm)”
1. 时间线:2026-01-15~2026-02-15 的开源新模型
先用一张时间线把“最近一个月”发生的事钉住(后面所有讨论都围绕这些版本展开):
本次覆盖的代表性模型/分支包括:
- GLM-5(2026-02-12):面向推理/代码/Agent 的大体量 MoE(官方描述 744B 参数、40B 激活),并给出强势的 Agent 评测表。
- MiniMax-M2.5(2026-02-12):强调“真实环境 RL + 高效低成本”,SWE Verified 达到 80.2。
- Ring-2.5-1T(2026-02-13):万亿参数混合线性注意力(Hybrid Linear Attention),主打长程执行与推理。
- Kimi K2.5(2026-01-27):原生多模态 Agentic MoE,并直接把 Agent Swarm 作为核心能力发布。
- Qwen3-Coder-Next(2026-02-02):专注 coding agent 的 Qwen3 新分支,强调 agentic training signal。
- Qwen3-ASR / ForcedAligner(2026-01-29):面向语音识别与强制对齐的工具型开源模型。
- Qwen3-TTS(2026-01-21):面向低延迟 streaming 的语音生成模型。
- Ming-flash-omni 2.0(2026-02-11):Any-to-Any 全模态(理解+生成)模型,主打统一音频通道与高动态视觉生成。
Baichuan-M3-235B(2026-02-09 README 更新):医疗增强大模型,强调“问诊→决策”链路与降幻觉训练。
2. 评测视角:把模型当成 Agent 的“脑”,而不是聊天机器人
做 Agent 时,最容易踩的坑是:
- 你用一个“会聊天”的模型,去做一个“要执行”的系统;
- 结果它能写得头头是道,却在工具调用、长上下文、错误恢复、并行协作上反复翻车。
所以本文采用一个更工程化的三层评测框架:
- 模型层(Brain):推理/代码/多模态、长上下文是否稳定、思考模式(thinking mode)能否控制。
- 接口层(Hands):OpenAI 兼容接口、tool calls 格式、JSON 输出约束、流式输出、缓存与续写。
- 系统层(Agent):规划与分解、并发执行(swarm)、检索与网页操作、代码执行、以及失败后的自我修复(retry/rollback)。
这三层里,2026 开年这波更新最“值钱”的往往是 2) 和 3):
- 评测表里开始出现 BrowseComp w/ context management 这种“系统能力指标”;
- 发布材料里开始把 “SWE-Agent scaffold” 或 “Agent Swarm” 写成第一卖点。
3. 两张关键对比图:谁更像“能干活的工程师”?
3.1 SWE-bench Verified:真实修 bug(能跑测试)
SWE-bench Verified 是典型的“编码 Agent 必考题”:给一个真实开源仓库的 bug,模型需要定位问题、改代码、跑测试,最后提交能通过验证的 patch。
从官方数据看(同一时期材料中的对比表):
- MiniMax-M2.5:80.2
- GLM-5:77.8
- Kimi K2.5:76.8
这几个分数的含义不是“谁更会写段子”,而是更接近:
在标准化脚手架(SWE-Agent/类似框架)里,模型能否稳定推进工程任务。
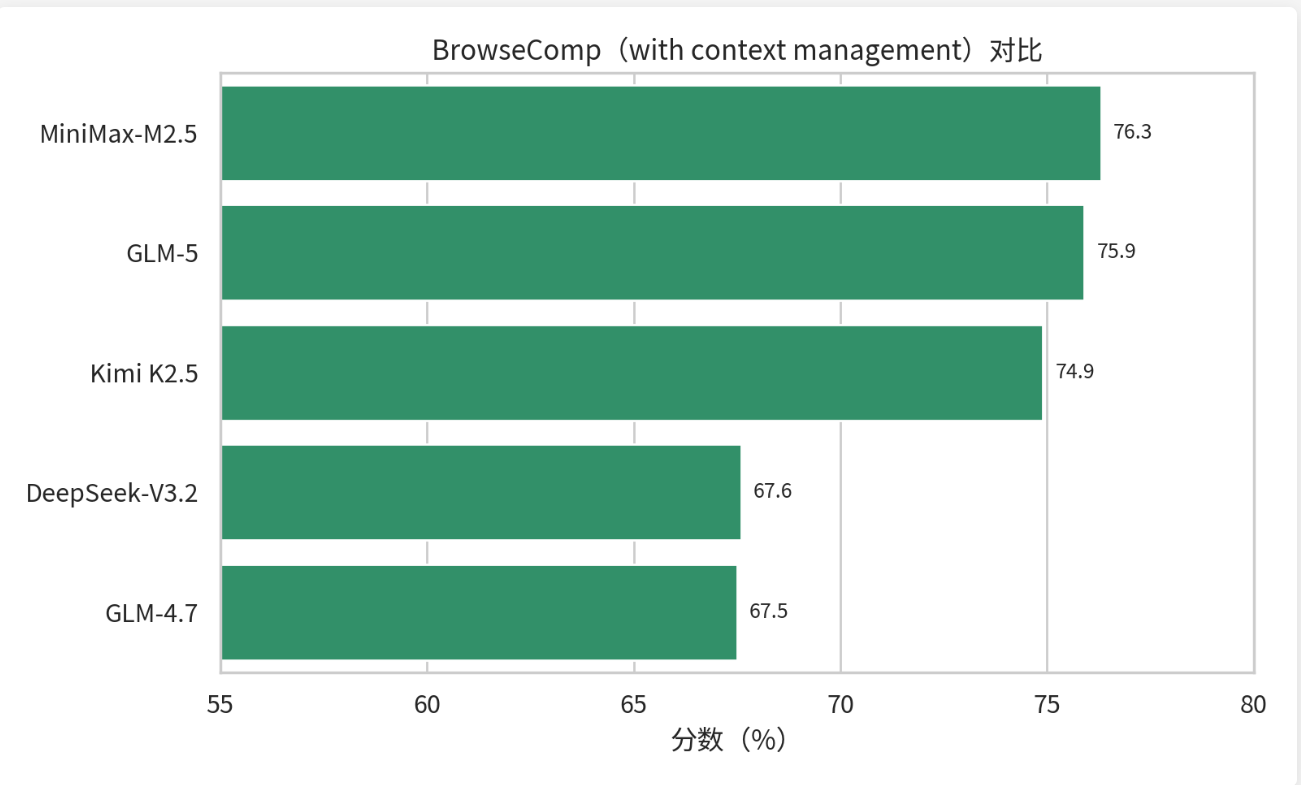
3.2 BrowseComp(with context management):上网查资料并保持上下文一致
对于研究型/运营型/分析型 Agent 来说,“能上网查、能读长文、能总结”是基本盘。关键难点在于:
- 检索结果多而杂;
- 需要跨网页、多轮阅读;
- 需要长期保持“我正在解决什么问题”。
注意这里的“with context management”基本等价于:不仅模型强,系统也要强(上下文压缩、记忆结构、引用追踪、反幻觉机制)。
4. 分模型评测:这波“新版本”究竟新在哪?
下面按“一句话结论 → 亮点 → 适用场景 → 风险点”来拆。
4.1 GLM-5:把“Agent能力”写进发布表格里的大模型
一句话结论: GLM-5 的核心卖点不是“更大”,而是“以 Agent 口径给出强指标,并强调与现成编码/工具框架兼容”。
- 亮点(官方材料):
- MoE 规模:官方描述 744B 参数、40B 激活;
- 训练侧强调 DeepSeek Sparse Attention、异步 RL(slime)等;
- 评测表把 SWE-bench Verified、BrowseComp、HLE-with-tools 等放到同一张表里。
- 适用场景:
- 企业内部“通用 Agent 底座”(写作/分析/检索/代码都要覆盖);
- 需要长上下文处理(官方材料在工具评测中使用到 200K 量级上下文)。
- 风险点:
- 模型体量大,对推理成本与部署形态要求高;
- 上下文很长时,系统层(记忆压缩/引用追踪)更关键,否则容易“越长越乱”。
4.2 MiniMax-M2.5:强调“真实环境 RL + 效率/成本”的工程派
一句话结论: M2.5 看起来像是在说:“我不只要分数,我还要你能在真实环境里以可控成本完成任务。”
- 亮点(官方材料):
- SWE-bench Verified 80.2,同时给出“平均耗时 22.8min”等效率指标;
- 训练强调在数十万真实环境中强化学习(environment RL),以及 Forge RL 框架。
- 适用场景:
- 成本敏感、但又想上“能修 bug 的编码 Agent”;
- 想做大量任务批处理(如自动修复、自动重构、自动生成测试)。
- 风险点:
- 需要关注其开源权重对应的推理服务支持(vLLM/sglang/自研)与函数调用格式一致性;
- Modified-MIT 等许可细节上线前要逐仓库核对。
4.3 Kimi K2.5:把“多代理并行(Agent Swarm)”当成产品能力发布
一句话结论: Kimi K2.5 的差异化是:它不只给你一个模型,还给你“怎么并行做事”的范式。
- 亮点(官方材料):
- 15T 视文混训,原生多模态;
- 256K 上下文;
- Agent Swarm:最多 100 个 sub-agents、最多 1500 次工具调用,并给出 PARL(并行增强 RL)方法描述。
- 适用场景:
- “研究/运营/投研/咨询”类任务:需要快速并行搜集信息、做摘要、做对比;
- “产品/设计/前端”类任务:图文混合输入输出、把视觉理解转成代码。
- 风险点:
- swarm 能力强,但对系统编排要求更高:任务拆分质量直接决定效果与成本;
- 工具调用规模上去后,必须引入配额/预算/回滚策略。
4.4 Qwen3-Coder-Next:coding agent 专用分支,强调“agentic training signal”
一句话结论: 如果你做“本地编码 Agent”或“公司内网代码助手”,Qwen3-Coder-Next 是最直接的工程选项之一。
- 亮点:
- 256K 原生上下文,配合 YaRN 可到 1M(README);
- 强调为 agentic coding 引入专门训练信号;
- 官方提到在 SWE-Agent scaffold 下 SWE Verified 70%+。
- 适用场景:
- 本地开发(IDE/CLI)+ 代码库级别理解;
- 与 OpenClaw/SWE-Agent 这类框架结合,做自动修复/自动重构。
- 风险点:
- 具体 license/模型矩阵要以各 HF 仓库为准;
- 1M 上下文不是“白送的”:系统层要做检索/摘要/引用,否则上下文越长越混乱。
4.5 Ring-2.5-1T:万亿参数 + 混合线性注意力,主打长程执行
一句话结论: Ring-2.5-1T 的看点不在传统“答题榜”,而在“新注意力形态 + 超长上下文执行”这条路线。
- 亮点(官方 README):
- 1:7 MLA + Lightning Linear Attention;
- 128K → 256K(YaRN)
- 强调长程任务与推理能力。
- 适用场景:
- 超长文档/超长流程的任务型 Agent;
- 需要把“记忆”更多交给模型结构而不是纯 RAG 的场景。
- 风险点:
- 公开材料中可直接引用的可比 benchmark 较少,落地需自测;
- 万亿体量带来的部署成本与吞吐压力不容忽视。
4.6 Ming-flash-omni 2.0:Any-to-Any 全模态,统一音频通道
一句话结论: 如果你要做“能听、能说、能看、还能生成视频/音效”的全模态 Agent,Ming-flash-omni 2.0 是这波里最典型的代表。
- 亮点(HF 模型卡):
- MoE 100B/6B active;
- 强调统一音频单通道(语音/音效/音乐)与高动态图像生成/编辑;
- 支持视频对话。
- 适用场景:
- 多媒体内容生产/剪辑/配音/脚本化视频;
- “客服+语音+屏幕理解”类实时 Agent。
- 风险点:
- 多模态链路的系统复杂度远高于纯文本:你需要更强的缓存、转码、对齐与安全策略;
- 许可与推理依赖要逐仓库确认。
4.7 Baichuan-M3-235B:医疗增强 + 低幻觉训练路线
一句话结论: 医疗场景比通用场景更讨厌幻觉,Baichuan-M3 的路线是“把问诊→决策流程当成训练对象”。
- 亮点(README):
- Fact-Aware RL 降幻觉;
- SPAR 分段 RL;
- 支持
thinking_mode=on这类可控思考接口; - HealthBench-Hard 44.4。
- 适用场景:
- 医疗问答、辅助分诊、临床路径摘要、病历结构化。
- 风险点:
- 医疗是高风险场景:即使模型开源,仍必须做合规、审计与人类兜底;
- 评测口径要用医疗专用基准与真实流程验证。
4.8 Qwen3-ASR / Qwen3-TTS:把“语音能力”拆成可组合的开源工具
一句话结论: 这波 Qwen3 的语音分支更像“工程组件”:你可以把 ASR、对齐、TTS 当作 Agent 的输入输出层来拼装。
- Qwen3-ASR + ForcedAligner(Apache-2.0):
- 52 语种/方言 ASR;11 语种强制对齐;
- 语言识别平均 97.9%;对齐 AAS 平均 42.9ms(对比表);
- 对 Agent 意义:把语音会议/访谈变成可检索的结构化文本。
- Qwen3-TTS(低延迟 streaming):
- 双轨 streaming,官方宣称延迟可低至 97ms;
- 对 Agent 意义:让“实时语音助手”不再像复读机,而更像对话。
5. 编程与 OpenClaw:把“模型能力”变成“能跑的 Agent”
下面给出一套最小可用的工程脚手架:
- 用统一的 OpenAI 兼容 client 对接本地/云端推理;
- 设计一组“烟囱测试”快速判断模型是否适合 Agent;
- 用 OpenClaw-style 的 Planner/Executor/Verifier 结构,把任务做成可控系统。
5.1 统一 OpenAI 兼容 Client(Python)
无论你用 vLLM/sglang/官方 API,只要是 OpenAI 兼容接口,都可以用同一段代码:
from openai import OpenAI
client = OpenAI(
base_url="<http://localhost:8000/v1>", # 例如 vLLM/sglang
api_key="EMPTY",
)
resp = client.chat.completions.create(
model="your-model-id",
messages=[
{"role": "system", "content": "你是一个严格输出 JSON 的助手。"},
{"role": "user", "content": "用 JSON 输出一个包含 name、age 的示例对象"},
],
response_format={"type": "json_object"},
)
print(resp.choices[0].message.content)为什么这段代码重要?
- 2026 这波模型大量强调 tool use / JSON / agentic coding;
- 但落地时,最常见问题不是模型不聪明,而是输出不稳定、schema 不合规、流式中断。
因此建议你把“接口层可用性”当成第一关。
5.2 一个 OpenClaw-style 的最小 Agent:Planner / Executor / Verifier
这里用极简伪代码展示结构(你可以映射到 OpenClaw 的具体实现):
from dataclasses import dataclass
from typing import List, Dict, Any
@dataclass
class ToolCall:
name: str
args: Dict[str, Any]
class Planner:
def plan(self, task: str) -> List[str]:
# 输出可执行的子任务列表
...
class Executor:
def run_step(self, step: str) -> str:
# 可能触发工具:search/click/read/run_code/git_patch ...
...
class Verifier:
def verify(self, task: str, evidence: str) -> bool:
# 例如:引用是否齐全?单测是否通过?结构化输出是否可解析?
...
class OpenClawLikeAgent:
def __init__(self, planner, executor, verifier):
self.planner = planner
self.executor = executor
self.verifier = verifier
def solve(self, task: str) -> str:
steps = self.planner.plan(task)
traces = []
for step in steps:
traces.append(self.executor.run_step(step))
evidence = "\n".join(traces)
if not self.verifier.verify(task, evidence):
# 失败时可以:缩小范围/改提示词/加检索/重试
...
return evidence把这个结构套到不同模型,你会立刻感受到差异:
- Kimi K2.5 更像“并行系统”,适合把
plan()输出成几十个并发 sub-agents; - Qwen3-Coder-Next / MiniMax-M2.5 / GLM-5 更适合作为
Executor的“编码大脑”; - Ring-2.5-1T 可能更适合长上下文的“持续执行”任务(但需要你自己测)。
5.3 快速烟囱测试:10 分钟判断一个模型能不能当 Agent
建议你用 4 类小任务做冒烟:
- 结构化输出:给 schema,看是否稳定输出 JSON;
- 工具调用:给 tool schema,看是否能正确调用与纠错;
- 代码修复:给一个最小 repo(含单测),看能否跑通;
- 检索总结:给一个问题,看能否“检索→引用→总结”。
下面给一个“代码修复”最小脚本轮廓(简化版):
import subprocess
from pathlib import Path
def run_tests(repo: Path) -> tuple[int, str]:
p = subprocess.run(["pytest", "-q"], cwd=repo, capture_output=True, text=True)
return p.returncode, p.stdout + p.stderr
# 你可以把模型输出的 diff 应用到 repo,再跑 tests
# 这就是 SWE-bench Verified 思路的最小复现你不需要一上来就跑完整 SWE-bench;先用 2~3 个公司内部小仓库就能快速筛模型。
6. 选型建议:按“你要的 Agent 类型”来选模型
把这一个月的变化落到工程选择上,可以用下面的“粗暴但有效”的映射:
- 本地/私有化 coding agent(IDE/CLI):优先关注 Qwen3-Coder-Next(长上下文 + agentic coding 信号),再用 MiniMax-M2.5 / GLM-5 做更强执行器。
- 企业通用 Agent(写作+检索+代码混合):GLM-5 与 MiniMax-M2.5 都是候选;你要重点比较的是:
- 你能否接受其部署成本;
- 你的系统是否有 context management(不然 BrowseComp 类任务很难发挥)。
- 高并发研究/运营型“信息工厂”:Kimi K2.5 的 Agent Swarm 思路更顺手,但你必须搭好预算控制与任务拆分。
- 全模态内容生产/实时语音助手:Ming-flash-omni 2.0 + Qwen3-ASR/TTS 的组合会很有吸引力:
- ASR 负责“听懂并结构化”;
- LLM 负责“规划与生成”;
- TTS 负责“实时说出来”。
- 医疗等高风险垂域:Baichuan-M3 是典型“把流程建模进训练”的路线,但必须配合合规、人类审核与审计。
7. 附录:数据与参考链接
- 模型总表(CSV):
models_overview_cn_open_llm.csv - 参考链接(按模型):
- GLM-5 官方博客:https://z.ai/blog/glm-5
- MiniMax M2.5 新闻页:https://www.minimax.io/news/minimax-m25
- MiniMax M2.5 HuggingFace 模型卡:https://huggingface.co/MiniMaxAI/MiniMax-M2.5
- Kimi K2.5 GitHub:https://github.com/MoonshotAI/Kimi-K2.5
- Kimi K2.5 博客:https://www.kimi.com/blog/kimi-k2-5.html
- Qwen3-Coder GitHub:https://github.com/QwenLM/Qwen3-Coder
- Qwen3-Coder-Next 博客:https://qwen.ai/blog?id=qwen3-coder-next
- Qwen3-ASR GitHub:https://github.com/QwenLM/Qwen3-ASR
- Qwen3-TTS 博客:https://qwen.ai/blog?id=qwen3tts-0115
- Ring-2.5 GitHub:https://github.com/inclusionAI/Ring-V2.5
- Ming-flash-omni 2.0 HuggingFace:https://huggingface.co/inclusionAI/Ming-flash-omni-2.0
- Baichuan-M3 GitHub:https://github.com/baichuan-inc/Baichuan-M3-235B