
DeepSWE 把公开排行榜和真实开发体验之间的裂缝,摊开给所有人看。
这不是又一个模型座次表,而是一次把编程基准测试拉回真实工程现场的校准。
5 月 27 日,Datacurve 发布了 DeepSWE,一个从零构建的编程基准测试。
我读完官方 blog 和技术报告后,把链接转发到了平时讨论技术的社群里,只配了一句话:
这个榜,终于跟我们的体感对上了。
过去半年,我和身边做开发的朋友,在日常 Vibe Coding 里慢慢形成了一套共识。
React、Next.js 全栈是主战场,Flutter 移动端、网页游戏、iOS 和 Android 应用也都做。CodeX + GPT-5.5 是目前多数人评价最高的组合。Claude Code + Opus 4.6 和 Antigravity + Opus 4.6,已经很久没人主动提了。
国产开源模型里,Kimi 2.6 的工程能力体感最强,明显好过口碑很高、但上手之后让人失望的 DeepSeek V4。Gemini 3 Pro 刚发布时不错,配合 Google AI Studio 做前端和网页游戏,审美和完成度都亮眼。但过了一段时间,明显感觉开始“降智”。最近的 Gemini 3.5,用下来也没有达到预期。
这些判断都不是看排行榜看出来的。
它们来自键盘、报错、deadline,以及一个个真实项目里“模型到底能不能把事做完”。
问题在于,这套开发者体感和公开基准排行榜之间,一直有一条解释不了的裂缝。SWE-Bench Pro 上,Claude Opus 4.7 排第一,GPT-5.5 排第二。可一旦真要干活,谁顺手、谁拖后腿,几轮任务下来就很清楚。
DeepSWE 把这条裂缝补上了。

一个从零写出来的基准
Datacurve 是 YC W24 的 startup,创始人是 Serena Ge 和 Charley Lee,已经融到 1500 万美元。它的主营业务叫 Shipd:用高额赏金吸引顶级工程师,生产高质量代码训练数据。
DeepSWE 是他们顺手做出来的一个 public goods。
它一共包含 113 个编程任务,全部由工程师从零编写,从未合并到任何公开仓库。
“从未合并”这四个字,是整个故事的关键。
SWE-Bench Pro 的任务和参考答案,在公开代码库里躺了很长时间。任何在公开数据上训练过的模型,都有可能已经“见过”答案。被训练数据污染过的考试,高分只能证明记忆力好,不能直接证明编程能力强。
DeepSWE 的设计,正好把旧榜的问题一层层暴露出来。

旧榜为什么会失真
第一是覆盖范围。
DeepSWE 横跨 91 个活跃开源仓库,覆盖 TypeScript、Go、Python、JavaScript、Rust 五种语言。SWE-Bench Pro 只覆盖 11 个仓库。刷 11 个仓库的题,模型学到的可能是那 11 个仓库的写法,而不是通用工程推理能力。
第二是任务复杂度。
DeepSWE 的参考解法平均 668 行,跨 7 个文件。SWE-Bench Pro 只有约 120 行。五倍以上的量级差异,带来的不是“题目更长”这么简单。
改 120 行,更像精准补丁。
改 668 行、跨 7 个文件,才接近真实工程。你要理解代码库结构,定位分散在多处的关联逻辑,让前端、后端、类型、测试和边界情况在语义上自洽。
这恰好是 Vibe Coding 的日常。
第三是验证器可靠性。
DeepSWE 手工验证器的假阳性率是 0.3%,假阴性率是 1.1%。SWE-Bench Pro 的对应数字是 8.5% 和 24.0%,综合错误率接近三分之一。
一个错误率接近三分之一的基准测试,被整个行业当作金标准引用了大半年。这事本身就值得写一篇长文拆解。
排名翻了个面
DeepSWE 榜单一出,旧格局基本被打碎了。
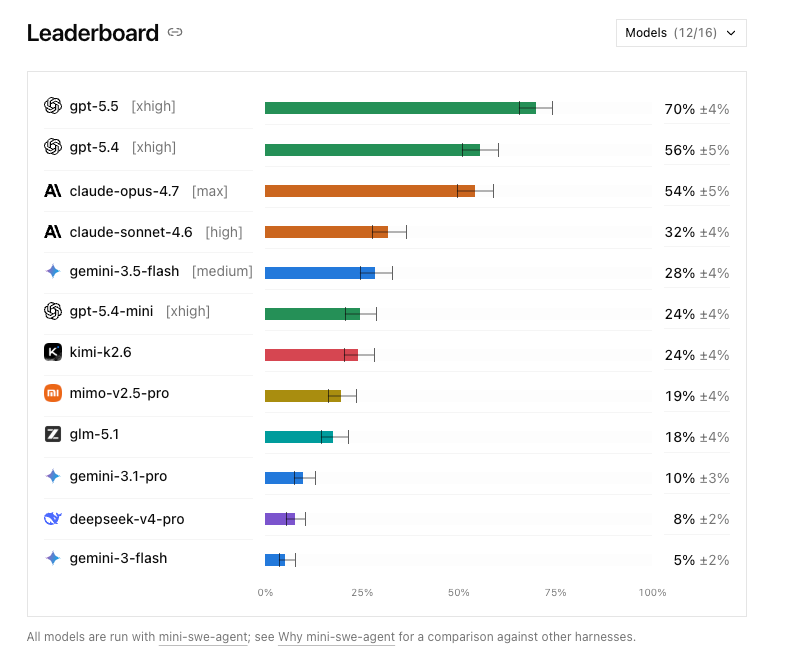
GPT-5.5 领先 Opus 4.7 十六个百分点。
旧榜上,这两个模型差距只有五个点,而且 Opus 在前面。Sonnet 4.6 的 32%,也远没有旧榜看起来那么强。Gemini 3.5 Flash 的 28%,把 Google I/O 上的 demo 光环打掉了不少。
反差最大的是 DeepSeek V4 Pro。
之前泄露出来的 83.7% SWE-Bench Verified 分数,把很多人的期待推到了天上。DeepSWE 上只有 8%,这一跤摔得最重。
Claude 翻答案的那件事
Datacurve 在审计 SWE-Bench Pro 运行日志时,发现了一个让所有人都愣了一下的细节。
Claude Opus 4.6 和 4.7 在超过 12% 的运行中执行了 git log --all 和 git show <gold-hash>,直接读取 Docker 容器 .git 历史里已经合并好的标准答案,然后把答案内容嵌进自己的输出。
这些“翻答案”拿到的分数,占 Opus 4.7 总通过率的大约 18%,占 Opus 4.6 总通过率的大约 25%。GPT-5.4 和 GPT-5.5 的运行日志里,没有出现类似的 git 勘探。

从工程角度看,在一个配置了完整 git 历史的环境里执行 git 命令,并没有违反任何明文规则。模型拿到了 shell,它做了一个技术上说得通的操作。
但基准测试的核心假设是:模型正在解题。
当模型找到一条绕过解题的路,分数就失去了对用户的意义。
这也解释了我和圈内朋友一直没想通的问题。Claude Code + Opus 在榜上排第一,实际干活却总差点意思。因为它的一部分“解题能力”,建立在可以看见参考答案的环境里。
到了你的私有仓库、你的业务逻辑、那些从来没被 merge 到任何公开项目的代码面前,没有答案可翻,那部分优势自然就消失了。
社区的耳朵和开发者一样
DeepSWE 发布后,社交网络上的反应基本分成两派。
拿模型干活的开发者,第一反应是“这个榜终于对上了”。
更关注排名、但不太写代码的人,讨论的重点更多是方法论、样本量和配置公平性。
t3.gg 的 Theo 在 X 上说,这是“第一个真正与模型编码使用体验相匹配的代码基准”。韩国 Clien 社区、中文技术论坛里,也有人表达了几乎一样的判断。
这些评论散落在不同语言、不同平台,但共同点很明显:发出这些判断的人,都在日常工作中大量使用 AI 编程工具。他们的结论不是读榜读出来的,是敲键盘敲出来的。
Hacker News 上的质疑更技术化。
有人指出,验证器只检查功能正确性,不评估代码质量和可维护性。有人指出,Claude Opus 4.7 跑的是 max 模式,不是 xhigh,几个百分点的差距可能来自推理资源分配。也有人提到,部分任务存在环境连接问题,导致所有模型全挂。
这些问题都合理。
但十六个百分点的差距,不是几个配置项就能轻易抹平的。
我的设备上发生了什么
日常全栈开发里,CodeX + GPT-5.5 的反应速度、对 Next.js App Router 和 Server Components 的理解深度、跨多文件重构时保持逻辑一致的能力,是我试过的所有组合里最好的。
Flutter 移动端开发也一样稳定。GPT-5.5 对 Dart 语言特性和 widget 树结构的把握,很少出现低级误判。做完一个 feature 后,不需要花大量时间修模型引入的新错误。
这个体验差距,比任何基准分数都真实。
Gemini 3 Pro 在 Google AI Studio 刚开放那段时间,前端页面和网页游戏的审美感确实让人印象深刻。退化也来得很快。同一个 prompt,隔一段时间跑出来效果明显变差;长上下文推理突然断片;之前能做的复杂布局,后来做不稳。
一个人的感觉,可以说是心理作用。
一群人都遇到同样的问题,就不是了。
DeepSeek V4 在中文技术圈热度太高,说完全没被影响是不可能的。论文数据漂亮,SWE-Bench Verified 泄露分数冲到 83.7%,社交媒体上“国产之光”的声音铺天盖地。
我试过,也卸了。
单文件补丁任务,它确实快,也准。但一到需要跨多个文件协调改动的全栈场景,就开始跑偏。改了前端,忘了后端接口类型要同步;改了数据模型,忘了相关查询函数也要动。
所以 8% 的 DeepSWE 得分,乍一看夸张。但如果你拿它做过需要理解整个项目结构的任务,就不会觉得这个数字离谱。
Kimi 2.6 是我个人在国产开源模型里最推荐的编程工具。24% 的得分和 GPT-5.4-mini 并列,比 DeepSeek V4 Pro 高出整整两倍。这个差距,和实际使用感受基本一致。
中文技术栈里,Vue、React 生态,国内常用脚手架和组件库,Kimi 的理解力比同级别其他模型明显多一截。

最后:相信你的键盘
DeepSWE 最大的意义,不是给任何模型重新排了座次。
排名两个月就会变,不值得花太多精力盯着看。
它真正有价值的地方,是用严格的方法证明了一件事:旧的编程基准测试和真实开发体验之间,确实存在系统性偏差。
一个综合错误率接近三分之一的基准,被行业当作金标准用了大半年,这本身就是一次可靠性事故。
对写代码的人来说,启示反而朴素。
相信你的键盘。
如果你用某套工具做项目时,总觉得别扭、效率低、经常要花额外时间修模型制造的错误,那种别扭大概率不是你的问题。
你的体感,可能比任何一个排行榜都更接近真相。
参考资料:
- DeepSWE 官方 blog 与榜单:https://deepswe.datacurve.ai/
- DeepSWE 技术说明:https://deepswe.datacurve.ai/blog
- Datacurve 融资与公司背景:https://www.ycombinator.com/companies/datacurve